Code
2024

Opti-CAM combines ideas from CAM-based and masking-based approaches for interpretability. It produces a saliency map suggesting what regions are responsible for a classifier prediction. The saliency map is a linear combination of feature maps, where weights are optimized per image such that the logit of the masked image for a given class is maximized. The code allows the reproduction of the results of our CVIU 2024 paper.

DoRA is a self-supervised image pretraining method tailored for learning from continuous videos. It leverages the attention from the [CLS] token of distinct heads in a vision transformer to identify and consistently track multiple objects within a given frame across temporal sequences. On these, a teacher-student distillation loss is then applied. Importantly, we do not use any off-the-shelf object tracker or optical flow network. This keeps our pipeline simple and does not require any additional data or training. The code allows the reproduction of the results of our ICLR 2024 paper.

We introduce a new strategy called for semantic segmentation "multi-target UDA without external data". The segmentation model is initially trained on the external data. Then, it is adapted to a new unseen target domain without accessing any external data. This approach is thus more scalable than existing solutions and remains applicable when external data is inaccessible. We demonstrate this strategy using a simple method, "unseen target knowledge distillation" (UT-KD), that incorporates self-distillation and adversarial learning, where knowledge acquired from the external data is preserved during adaptation through "one-way" adversarial learning. The code allows the reproduction of the results of our arXiv 2024 paper.
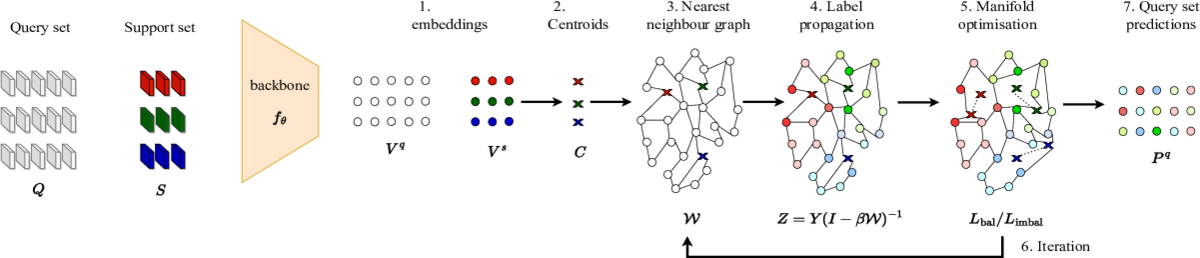
Adaptive Manifold is an algorithm for transductive few-shot learning on class-imbalanced data. It exploits the underlying manifold of the labeled examples and unlabeled queries by using manifold similarity to predict the class probability distribution of every query. It is parameterized by one centroid per class and a set of manifold parameters that determine the manifold. All parameters are optimized by minimizing a loss function that can be tuned towards class-balanced or imbalanced distributions. The code allows the reproduction of the results of our WACV 2024 paper.
2023
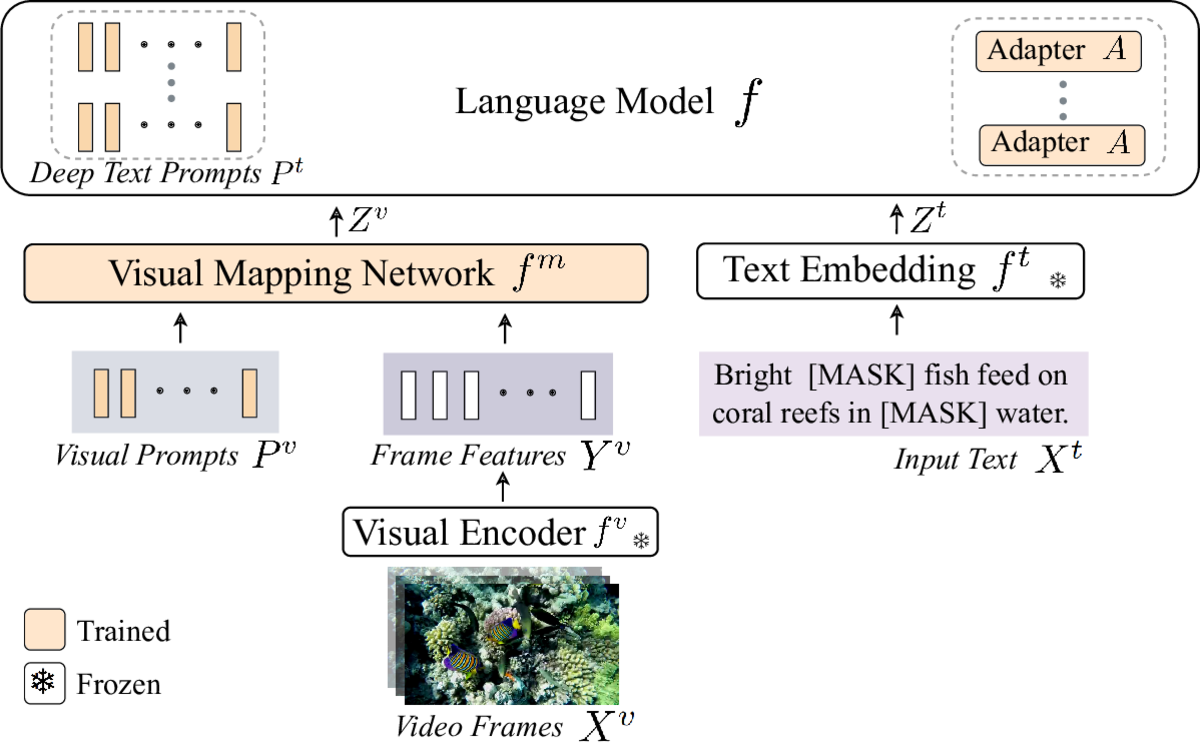
ViTiS is a parameter-efficient method for adaptation of large-scale pretrained vision-language models on limited data, addressing challenges such as overfitting, catastrophic forgetting, and the cross-modal gap between vision and language. It combines multimodal prompt learning and a transformer-based mapping network, while keeping the pretrained models frozen. We apply it to Zero-Shot and Few-Shot Video Question Answering. The code allows the reproduction of the results of our CLVL/ICCV 2023 paper.

SimPool is a simple attention-based pooling mechanism as a replacement of the default one for both convolutional and transformer encoders. Whether supervised or self-supervised, it improves performance on pre-training and downstream tasks and provides attention maps delineating object boundaries in all cases. SimPool is the first method to obtain attention maps in supervised transformers of at least as good quality as self-supervised, without explicit losses or modifying the architecture. The code allows the reproduction of the results of our ICCV 2023 paper.
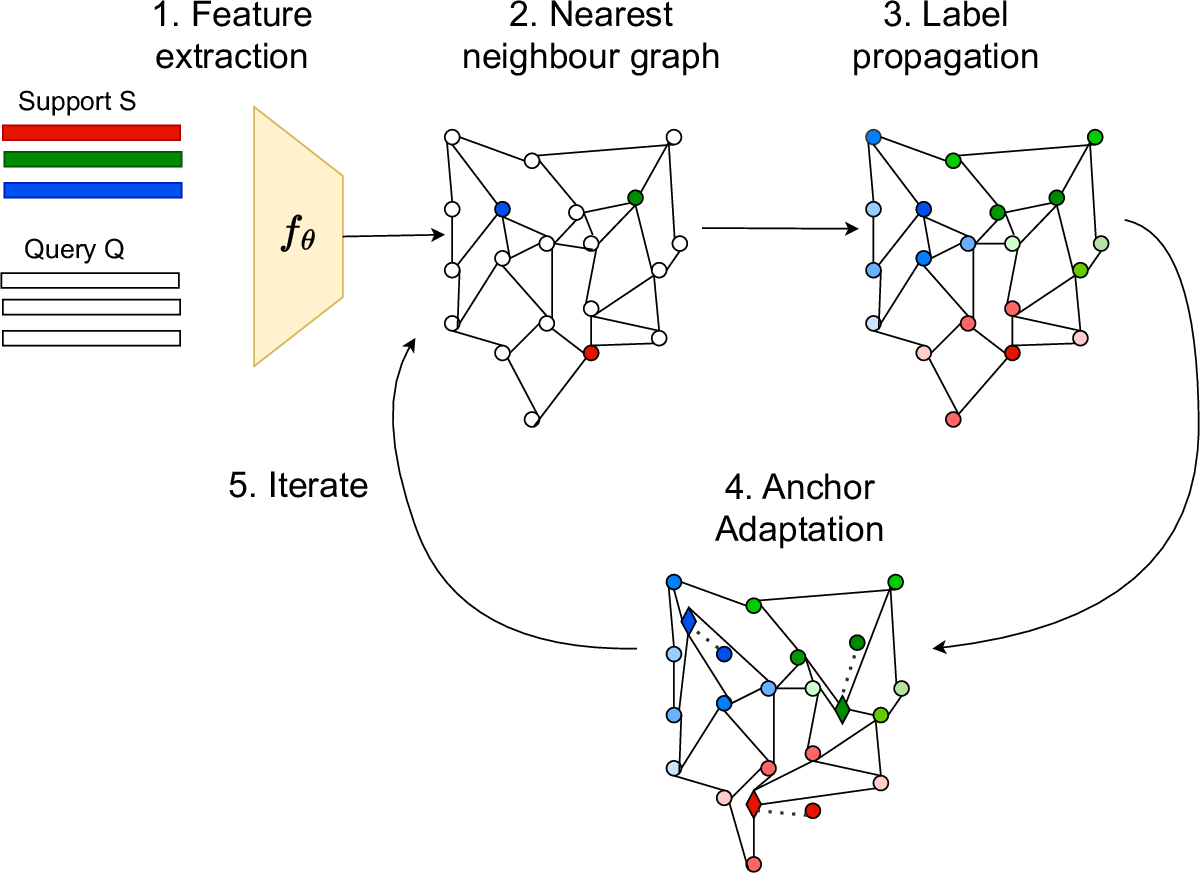
In the context of transductive inference for few-shot learning, label propagation infers pseudo-labels for unlabeled data by using a graph that exploits the manifold structure of the data. Adaptive anchor label propagation (A2LP) is an algorithm that adapts the feature embeddings of the labeled data by minimizing a differentiable loss function, optimizing their positions in the manifold in the process. The code allows the reproduction of the results of our ICIP 2023 paper.

PartNeRF is a part-aware generative model for editable 3D shape synthesis. It does not require explicit 3D or part supervision and is able to produce textures. It generates objects as a set of locally defined NeRFs, augmented with an affine transformation. This enables editing operations such as applying transformations on parts, mixing parts from different objects etc. The color of each ray is only determined by a single NeRF. As a result, altering one part does not affect the appearance of the others. The code allows the reproduction of the results of our CVPR 2023 paper.
2022

Metric Mix, or Metrix, is an algorithm for mixup-based interpolation as a data augmentation method for metric learning. It uses a generalized formulation that encompasses existing metric learning loss functions that is modified to accommodate for mixup. Mixing takes place at the input space, intermediate representations as well as the embedding space. It refers to both examples and target labels. The code allows the reproduction of the results of our ICLR 2022 paper.

In the context of self-supervised pretraining of vision transformers, this is a masking strategy that can be used as an alternative to random masking for dense distillation-based masked image modeliing (MIM) as well as plain distillation-based self-supervised learning on classification tokens. In particular, in the distillation-based setting, a teacher transformer encoder generates an attention map, which we use to guide masking for the student. The code allows the reproduction of the results of our ECCV 2022 paper.

This is a mixup-based data augmentation method, where we geometrically align two images in the feature space. The correspondences allow us to interpolate between two sets of features, while keeping the locations of one set. The code allows the reproduction of the results of our CVPR 2022 paper.
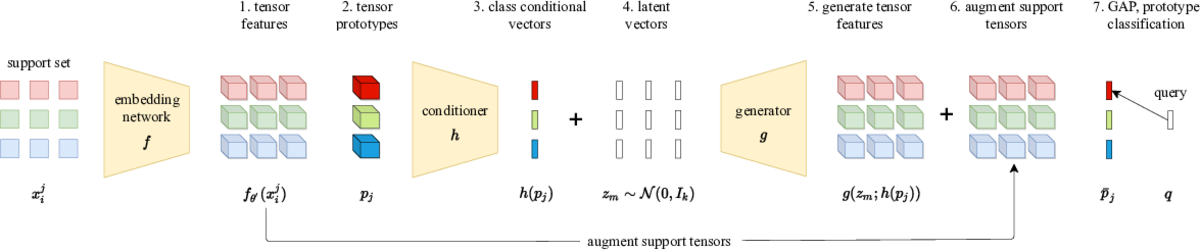
This is a simple synthetic data generation method few-shot learning. It involves a simple loss function for training a feature generator and it learns to generate tensor features instead of vector features. The code allows the reproduction of the results of our WACV 2022 paper.
2021

This is an algorithm for transductive and semi-supervised few-shot learning. It leverages the manifold structure of the labeled and unlabeled data distribution to predict pseudo-labels, while balancing over classes and using the loss value distribution of a limited-capacity classifier to select the cleanest labels, iteratively improving the quality of pseudo-labels. The code allows the reproduction of the results of our ICCV 2021 paper.

This is a Video Question Answering (VideoQA) method, where we address understanding of stories in video such as movies and TV shows from raw data, without external sources like plot synopses, scripts, video descriptions or knowledge bases. We treat dialog as a noisy source to be converted into text description via dialog summarization, much like recent methods treat video. The input of each modality is encoded by transformers independently, then we fuse all modalities using soft temporal attention for localization over long inputs. The code allows the reproduction of the results of our ICCV 2021 paper.
2020

Focusing on instance-level image retrieval, we study an asymmetric testing task, where the database is represented by the teacher and queries by the student. Inspired by this task, we introduce a novel paradigm of using asymmetric representations at training. This acts as a simple combination of knowledge transfer with the original metric learning task. The code allows the reproduction of the results of our CVPR 2021 paper.

The goal of neural architecture search is to automatically find the optimal network architecture, that is, the optimal succession and interconnection of layers. This is an intractable combinatorial optimization problem. We define a fully-dense super-network, out of which we select the most important connections by pruning. Still, training a deep super-network is not practical, so we devise a greedy algorithm: We grow the super-network a few layers at a time, training it and pruning its connections at each iteration. The code allows the reproduction of the results of the 2020 MSc thesis.

This is a Python implementation of ASMK. There are minor differences compared to the original ASMK method (ICCV 2013) and Matlab implementation, which are described in the HOW paper (ECCV 2020).
2019

This is a deep active learning framework allowing a systematic evaluation of different acquisition functions with or without methods that make use of the unlabeled data during model training. In particular, this includes (i) unsupervised pre-training, as implemented by DeepCluster, and (ii) semi-supervised learning, as implemented by our deep label propagation. The code allows the reproduction of the results of our ICPR 2020 paper.

We learn a classifier from few clean and many noisy labels. The structure of clean and noisy data is modeled by a graph per class and graph convolutional networks are used to predict class relevance of noisy examples. This cleaning method is evaluated on an extended version of a few-shot learning problem, where the few clean examples of novel classes are supplemented with additional noisy data. The code allows the reproduction of the results of our ECCV 2020 paper.

We learn an object detector from few weakly-labeled images and a larger set of completely unlabeled images. The main idea is to learn a classifier first in a semi-supervised setting, then use it as a teacher to train a student network on a weakly-supervised object detection task. The student detector is based on PCL weakly supervised object detector. The code is not public yet.

We depart from the standard setting of few-shot learning in that the representation is obtained from a classifier pre-trained on a large-scale dataset of a different domain, while the base class data are limited to few examples per class and their role is to adapt the representation to the domain at hand rather than learn from scratch. In doing so, we obtain from the pre-trained classifier a spatial attention map that allows focusing on objects and suppressing background clutter. The code is not public.
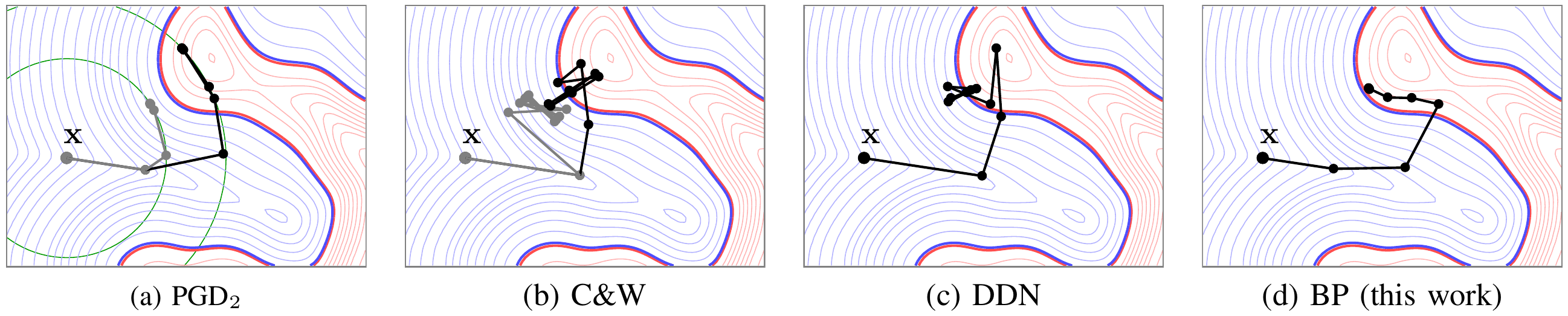
BP is an adversarial attack that reduces the distortion of the perturbation while operating under quantization at very few iterations. The attack is also used to build more robust models by using BP in adversarial training as a defense. The code allows the reproduction of the results of our TIFS 2021 paper.
2018


Dense classification over feature maps studies for the first time local activations in the domain of few-shot learning. Implanting, that is, attaching new neurons to a previously trained network to learn new, task-specific features, achieves for the first time fine-tuning of the entire network to convergence without overfitting on novel classes. The code is not public.

DSM exploits the sparsity of convolutional activations to detect local features and provide spatial matching for image retrieval. Without modifying the network architecture or re-training, without even local descriptors or vocabularies, deep spatial matching sets a new state of the art in particular object retrieval with a compact representation. The code allows the reproduction of the results of our CVPR 2019 paper.

This is a particular form of photorealistic on-manifold adversarial examples that are actually more effective than ordinary off-manifold examples, despite the spatial constraints: our attack has the same probability of success at lower distortion. The perturbation is locally smooth on the flat areas of the input image, but it may be noisy on its textured areas and sharp across its edges. This operation relies on Laplacian smoothing, which we integrate in the attack pipeline. The code allows the reproduction of the results of our JIS 2020 paper.
2017
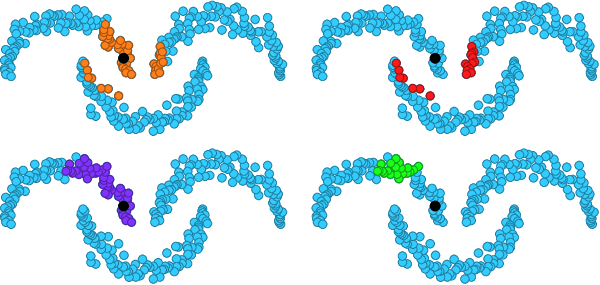
MoM is one of the very few self-supervised metric learning methods. Building on findings of manifold similarity, it learns a representation space where Euclidean neighbors are determined according to manifold neighbors in the original feature space. It is applied to fine-grained classification as well as particular object retrieval.

GOD captures discriminative patterns from regional CNN activations of an entire dataset, suppressing background clutter. A saliency measure is defined, based on a centrality measure of a nearest neighbor graph constructed from regional CNN representations of dataset images. Salient regions are then detected using an extended version of expanding Gaussian mixture. The code is not public yet.
2016
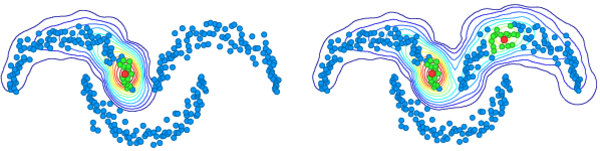
Diffusion is a manifold search method that uses a random walk on the nearest neighbor graph of a dataset. It has been extended to a spectral approach and a hybrid variant of the two for image retrieval. The code and data allows the reproduction of the results of our CVPR 2017 paper. In particular, we provide the descriptors used and the necessary ground-truth files for mAP evaluation. We also make available the approximate $k$-NN graph computed off-line for large-scale datasets.

In image classification, it has been common to learn mid-level discriminative parts, even before deep learning. Discovery of discriminative parts casts this as a quadratic assignment problem, allowing the use of a number of optimization algorithms on top of CNN representations. Unsupervised part learning extends this work by dispensing the need for class labels during part learning. It is applied equally to classification and instance retrieval, bringing significant gains to both. The code is not public.

PyNet is a minimal Python library for dynamic automatic differentiation. The focus is on simplicity and it is meant to accompany the differentiation lecture of Deep Learning for Vision course. It provides a tape-based automatic differentiation mechanism similar to that of PyTorch, allowing dynamic computational graph creation in plain Python code, including loops, conditionals etc. The initial implementation has included both a CPU backend in NumPy and a GPU backend in Neon. This version includes only the CPU backend and is meant for educational purposes.
This is a Python/Spark implementation of LOPQ. On top of CNN features, it has been used to power image similarity search on the entire Flickr collection.
2015
Y. Kalantidis: Framework and baselines for large-scale (100M) experiments. This includes extraction of CNN features for the 100M collection using Caffe and a distributed $k$-means baseline implemented in Spark.

IQM is an extremely efficient clustering algorithm operating on an extremely compressed data representation, for instance 26 bits/vector. It is a variant of $k$-means that quantizes vectors and uses inverted search from centroids to cells, while dynamically determining the number of clusters, following AGM. Using global CNN image representations, IQM scales up to clustering of a collection of 100M images in less than an hour on a single processor.

$k$-d GeRaF is a data structure and algorithm for approximate nearest neighbor search in high dimensions. It improves randomized forests by introducing new randomization techniques to specify a set of independently constructed trees where search is performed simultaneously, hence increasing accuracy. We omit backtracking, and we optimize distance computations.
2014

EBD is a compact representation for image retrieval. It explicitly detects visual bursts in an image at an early stage, using clustering in the descriptor space. The bursty groups are merged into meta-features, which are used as input to image search systems. It achieves compressing image representations by more than 90% without significant loss in performance. This is a demo version, available upon request.
2013
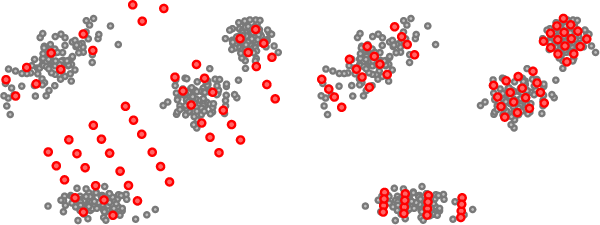
LOPQ a method for approximate nearest neighbor search that has remained state of the art for several years at a scale of one billion vectors. Leveraging the very same data structure that is used to provide non-exhaustive search, that is, inverted lists or a multi-index, the idea is to locally optimize an individual product quantizer per cell and use it to encode residuals. Local optimization is over rotation and space decomposition. This code is for demonstration only. Pre-computing projections for all queries is only done to facilitate parameter tuning and is suboptimal.

ASMK is a method for image search using local features and a combination of inverted files with compact binary descriptors. This model encompasses as special cases aggregated representations like VLAD and matching techniques such as Hamming Embedding. Making the bridge between these approaches, it takes the best of existing methods by combining an aggregation procedure with a selective match kernel. It has been a state of the art method before deep learning and it also applies to CNN features. The code allows the reproduction of the results of our ICCV 2013 paper as well as part of the experiments of revisited Oxford and Paris.

DRVQ is a fast vector quantization method in high-dimensional Euclidean spaces under arbitrary data distributions. It is an approximation of $k$-means that is practically constant in data size and applies to arbitrarily high dimensions but can only scale to a few thousands of centroids. As a by-product of training, a tree structure performs either exact or approximate quantization on trained centroids, the latter being not very precise but extremely fast. The combination of C++ recursive virtual functions for tree implementation with Matlab-like syntax for matrix operations has allowed fast prototyping, readable code and optimal performance in one piece of software.

ivl2 is an effort to re-design and re-implement ivl in the C++11 language standard. In contrast to ivl, which has targeted wide adoption, this is an experimental effort targeting exploitation of latest progress in the language to simplify its implementation and generalize its functionality and syntax. It makes full use of new features including variadic templates, template aliases, type inference, rvalue references and move semantics.
Its design is centered around a small number of orthogonal concepts that can be combined in arbitrary ways to yield an extremely powerful syntax. Among others, it offers a unique extension of std::type_traits and std::tuple, going far beyond the standard design to support views, expression templates, algorithms, and a unique common interface to tuples and static/dynamic arrays. It generalizes C++ iterators and D ranges. It overloads all C++ operators and functions to automatically support arbitrary combinations of scalars, arrays or tuples in an arbitrary number of arguments, which is not possible with ivl or any C++98 code.
ivl2 is a complex and abstract piece of software consisting of hundreds of source files. It offers a unique blend of features not currently available in any other library or language. It is written from scratch and the code is clean, organized and optimized.
2012

To reduce the space required for the index in large scale search, several methods focus on feature selection based on multiple views. In practice however, most images are unique, in the sense that they depict a unique view of an object or scene in the dataset and there is nothing to compare to. SymCity selects features in such unique images by self-similarity. In effect, we detect repeating patterns or local symmetries and select the participating features. The method itself is a variant of HPM, called Hough pyramid self-matching (HPSM) and maintains the same retrieval performance using only 20% of the required memory. The code is not public.

2011

This is the production version of AGM, allowing the reproduction of the results of our ECCV 2012 paper. The code is not public.
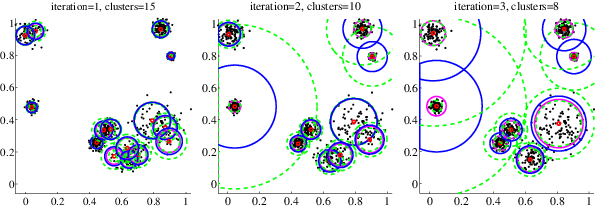
AGM is a clustering method that combines the flexibility of Gaussian mixtures with the scaling properties needed to construct large visual vocabularies for image retrieval. The algorithm can dynamically estimate the number of clusters, which is referred to as expanding Gaussian mixture (EGM). It also provides significant speed-up by employing approximate nearest neighbor search in assigning points to clusters, which is referred to as approximate Gaussian mixture (AGM). This is a demo version on a toy 2D example. The production version is not public.
2010

Scene maps refers to a representation of image collections used for large scale image search and mining, and applied to location and landmark recognition. Starting from a geo-tagged dataset, we first group images geographically and then visually, where each visual cluster is assumed to depict different views of the the same scene. We align all views to one reference image and construct a 2D scene map by preserving details from all images while discarding repeating visual features. A scene map thus collectively represents a scene as seen from different viewpoints. The indexing, retrieval and spatial matching scheme then operates directly on scene maps. All clustering operations are based on kernel vector quantization (KVQ). The code is not public.
2009

This is the production version of FMH. The code is not public.

FMH is a method for image indexing and retrieval, which integrates appearance with global image geometry in the indexing process, while enjoying robustness against viewpoint change, photometric variations, occlusion, and background clutter. To handle its increased memory requirements, hashing has been subsequently substituted with an automated and unsupervised feature selection model, leading to feature map similarity (FMS). This version is a prototype of the original idea on a toy 2D example. It is available upon request.
2008

This is a local feature detector originally applied to action recognition and then to salient event detection and movie summarization. It uses a multi-scale volumetric representation of the video and involves spatiotemporal operations at the voxel level. Saliency is computed by a global minimization process constrained by pure volumetric constraints, each of them being related to an informative visual aspect, namely spatial proximity, scale and feature similarity (intensity, color, motion). Points are selected as the extrema of the saliency response and prove to balance well between density and informativeness. The code is not public.
2007
2008: N. Skalkotos
2009-2013: K. Kontosis

ivl a full-header template C++98 general purpose library with convenient and powerful syntax. It extends C++ syntax towards mathematical notation, while making use of language features like classes, functions, operators, templates and type safety. It allows simple and expressive statements, while taking care of the underlying representation and optimization. Often resembling a new language, it targets abstract, concise, readable, yet efficient code. It supports the principle that the path from theory through rapid prototyping to production quality software should be as short as possible. In fact, the actual code should not differ much from pseudocode.
ivl features static and dynamic arrays, ranges, tuples, matrices, images and function objects supporting multiple return arguments, left/right overloading, function pipelining and vectorization, expression templates, automatic lazy evaluation, and dynamic multi-threading. Other features include sub-arrays and other lazy views of one- or multi-dimensional arrays and tuples, STL-compatible and multidimensional iterators, and extended compound operators. It is easy to use, with most syntax being self explanatory. It is fully optimized, with minimal or no runtime overhead, no temporaries or copies, and with most expressions boiling down to a single for loop.
ivl core is a header-only library, with no need for separate linking. It is fully template, supporting user-defined types. Separate modules are available that smoothly integrate with LAPACK, OpenCV and Qt for linear algebra, computer vision and GUI respectively. In each case, ivl shares its data representation with the underlying external library and combines its convenient syntax with a rich collection of software. Separate linking is needed for the modules used, since external libraries are not template.
The library is available as open source under a dual LGPL3.0 and GPL2.0 license at SourceForge and at its dedicated web site, which includes extended examples and documentation. A unique article ivl by example explains in less than eight pages how to build a randomized decision forest classifier from scratch with ivl, including the complete code of just 120 lines. The article and code behave like one entity, as in literate programming.
Over the years, ivl has been influenced by several C++ numerical libraries, for instance Eigen, or Boost.Multi-Array and Boost.Tuple for data representation and manipulation. At a more foundational level, it includes its own template metaprogramming library similar to Boost.MPL, heavily used for code optimization. A great motivation has been the Matlab language syntax, and in this sense a related project is Armadillo. Most of this syntax is supported, without the computational overhead and other known issues. In fact, ivl provides a unique integration of all the above functionalities.
Applications
2008
Core search engine: Y. Kalantidis, G. Tolias C++ 2008-2012
Explore/Routes: Y. Kalantidis, G. Tolias C++, PHP, Javascript based on Scene-maps 2011
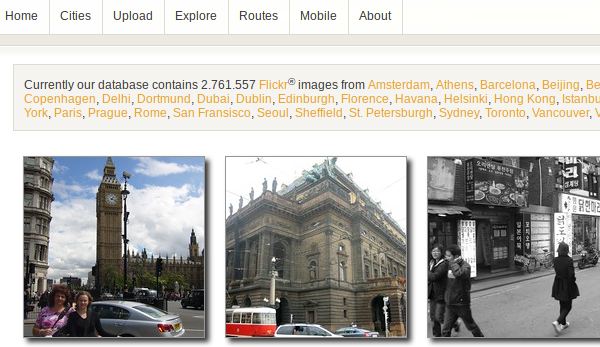
VIRaL is a visual search engine available online since 2008. The query is an image, either uploaded, fetched from a given URL, or chosen from the its database. Given this single image, it retrieves visually similar images and estimates its location on the map. It also suggests tags that may be attached to the query image, identifies known landmarks or points of interest, and provides links to relevant Wikipedia articles. Its database contains 2.7M Flickr images from 43 cities in the world. It is able to recognize tens of thousands of landmarks.
Additional applications enhance its user experience. VIRaL Explore enables browsing of the entire VIRaL image collection on the world map. Starting in a given city or at any zoom level on the map, it places icons corresponding to grouped photos, along with landmark names and Wikipedia links, if applicable. Photos are grouped off-line according to whether they depict the same object, building, or scene, and most popular groups are shown on the map, according to zoom level. VIRaL Routes offers a unique browsing experience of personal photo collections. Collections are processed off-line to identify where they were taken and group them by scene; a route is then constructed on the map, showing icons of visited places.
VIRaL targets general public to demonstrate results of our research. It has been disseminated in several technical and wide-audience venues. It is a unique application, and one of the very few non-commercial CBIR engines listed by Wikipedia that is really operating online.
Binaries
2011
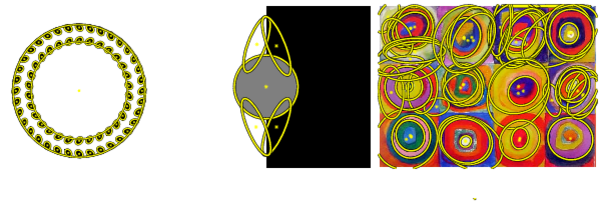
WaSH is a local feature detector. Given an input image, it computes a list of detected features, optionally with descriptors. It begins from sampled edges and is based on shape stability measures across the weighted $\alpha$-filtration, a computational geometry construction that captures the shape of a non-uniform set of points. Detected features are blob-like and include non-extremal regions as well as regions determined by cavities of boundary shape.
2010

HPM is a spatial matching method applied to geometry re-ranking for large scale search. It is based on a relaxed spatial matching model, which applies pyramid matching to the Hough transformation space. It is invariant to similarity transformations and free of inlier-count verification. It imposes one-to-one mapping and is flexible, allowing non-rigid motion and multiple matching surfaces or objects. It is linear in the number of correspondences and extremely fast in practice.
2009

MFD is a local feature detector. Given an input image, it gives access to all intermediate results including a (weighted) distance transform, (weighted) medial axis, an image partition generalizing topological watershed, and the detected features with optional descriptors using the VGG software. MFD also provides detailed statistics through several commands and options, including interactive visualization and debugging. It can operate in batch mode, optionally recursing subfolders. It has a special mode for binary images providing faster implementation, useful for binary distance transform and medial axis. In this case it also offers sub-pixel accuracy. The code is highly optimized, with running times in the order of 0.5 seconds for an image of 1Mpixel. A 15-page documentation is provided.
Data
2024

How important is it for training and evaluation sets to not have class overlap in image retrieval? We revisit Google Landmarks v2 clean, the most popular training set, by identifying and removing class overlap with Revisited Oxford and Paris, the most popular evaluation set. By comparing the original and the new RGLDv2-clean on a benchmark of reproduced state-of-the-art methods, our findings are striking. Not only is there a dramatic drop in performance, but it is inconsistent across methods, changing the ranking.

The Walking Tours dataset is a unique collection of long-duration egocentric videos captured in urban environments from cities in Europe and Asia. It consists of 10 high-resolution videos, each showcasing a person walking through a different environment, ranging from city centers to parks to residential areas, under different lighting conditions. A video from a Wildlife safari is also included to diversify the dataset with natural environments. The dataset is completely unlabeled and uncurated, making it suitable for self-supervised pretraining.
2017

RevOP is an image retrieval benchmark. It is the result of revisiting the two most popular image retrieval datasets, Oxford5k and Paris6k. We provide new annotation for both datasets with an extra attention to the reliability of the ground truth. All co-authors have independently annotated the entire dataset; the final annotation is the result of merging all individual contributions with an automated voting process. We introduce 15 new, more difficult queries per dataset and update the evaluation protocol by introducing three new settings of varying difficulty. We also create a new set of one million challenging distractors. The package includes Matlab and Python code to download and process the data and evaluate results on the new benchmark.
2016

This is a new version of the INSTRE benchmark for instance-level object retrieval and recognition. It has been developed as part of our work on diffusion. In particular, we are re-hosting the dataset at Inria because the original version is unavailable, we introduce a new evaluation protocol that is in line with other well known datasets and we provide a rich set of baselines to facilitate comparisons.
2011
This is an annotated logo dataset downloaded from Flickr group Identity + Logo Design and contains more than 4000 logo classes/brands in total. It consists of a training, a distractor and a query set, containing respectively 810 images with bounding boxes labeled into 27 classes, 4207 logo images/classes depicting clean logos and 270 images, half of which are annotated into 27 training classes and the other half do not depict logos.

WC2M Consists of 2.2M geo-tagged images from 40 cities, crawled from Flickr using geographic queries covering a window of each city center. It is meant to be used as a distractor set along with any annotated test set for image retrieval. It also includes the test set of EC1M dataset and is a superset of both EC1M and EC50k. The dataset is challenging because both the test set and the distractors mostly depict urban scenery.
2010

EC1M Consists of 909k geo-tagged images from 22 European cities, crawled from Flickr using geographic queries covering a window of each city center. A subset of 1,081 images from Barcelona is annotated into 35 groups depicting the same scene; 17 of the groups are landmark scenes and 18 are non-landmark. Annotation is based respectively on tags and visual search / manual clean-up. In total, 157 of those images are defined as queries (up to 5 per group). Images of the remaining 21 cities are used as distractors. Most depict urban scenery like the ground-truth, making a challenging distractor dataset.

EC50k consists of 50,767 geo-tagged images from 14 European cities, crawled from Flickr using geographic queries covering a window of each city center. A subset of 778 images from 9 cities are annotated into 20 groups depicting the same scene. Annotation is based on tags and visual search / manual clean-up. In total, 100 of those images are defined as queries (5 per group). Images of the remaining 5 cities are used as distractors. Most depict urban scenery like the ground-truth, making a challenging distractor dataset.